The "Myth" of Mythos
or How to Navigate the Hype


TL,DR: We are living through the greatest moment of technical excitement in decades, and at the same time an avalanche of misinformation about what frontier models can and cannot do in security. This article argues three things: that we will have more vulnerabilities deployed in the world, not fewer (Jevons effect); that the asymmetry between spelling and security is not commercial but computational (Rice, undecidability); and that finding vulnerabilities is a property of a system with a human in the loop, not of a model. The practical conclusion: most organizations should stop worrying about hypothetical master keys and start remediating the backlog they already have.
Since January 2026 I have lived through the greatest period of technological excitement of my life. I’m 44 now, and I’ve gone through several inflection points: having a 286 at age 8, then discovering that viruses existed (software that copies itself), then the Internet and its universe of information, learning that Linux existed and that I could run a Unix on a 486, being part of a community like Debian, getting a handle on Nix and NixOS, and now coding agents. It isn’t new for me to live through the moment when everything you knew stops being useful and you have to relearn. But only Linux and code-writing LLMs are comparable in magnitude.
In January 2026 I called the CEO of the company and said: “Vladi, the programming workflow has changed. Claude Code CLI and Opus 4.6 do different things. I’m asking for authorization to ban direct programming at Fluid Attacks and, starting February 1st, to give proper licenses to the entire engineering team. Since that is the only thing changing, we can treat it as a temporary experiment and compare our process metrics — mature and in place for years — against those of February and March.” They backed me, and here we are.
It might seem this was the transformation, but ever since LLMs broke out in 2023 — a moment that didn’t hit me with the same intensity — we started building a separate engineering department, attached to the Analytics division, so we could experiment with the new stacks available and leverage our vision for vulnerability management. The first bet was to try to hire experts in the field, which instead yielded talent who wanted to learn about it rather than people who already knew. So we decided, radically, to move internal engineers into the new area and start attacking multiple problems. Since 2024 we have in production vulnerability detection agents, prioritization models, dynamic patch generators, correlators between threat models and vulnerabilities, code contextualizers, AI-powered Pull Request analyzers, and countless internal tools not worth mentioning here. This context matters because it makes one thing clear: the excitement of January hit me even though we had been working across many AI areas for years.
This moment of excitement is the moment when you open a door and see a new world. It’s like seeing colors you hadn’t seen, smelling smells you hadn’t smelled, and they keep appearing and growing. A moment when I see a countless world of possibilities for us and for humanity. A moment when I believe that not only will software be better and tackle more problems, but that mathematics and the world of management will finally enter into symbiosis. Applying operations research used to be a crazy dream in any company that has to move fast. Now Monte Carlo analyses and assignment problems get solved beautifully in an hour, just by asking the right questions. It isn’t only software: it’s mathematics and rigor in the service of management.
I’m ecstatic to be living this moment of the world, to see how day by day we get better at many things, how the team is slowly starting to believe, and how we do things that used to be impossible. Rapidly increasing test coverage, remediating vulnerabilities faster, putting our dumb tests to the test with mutation testing, writing Rust, shipping faster and more deterministic components that save time for our clients. It isn’t only excitement: it’s watching it spread across the team.
And yet all this excitement turns against me when press announcements start coming out in which Anthropic says it will release a component that reviews code security. Every security company’s stock drops, and I ask myself: what’s the logic? Okta — one of the most relevant companies for the future of AI — drops? Why does something drop that has nothing to do with this? The world now believes Anthropic will replace the category with its next model. It already happened with the SaaS apocalypse; then they pull it off in another category and it lands. It makes very little sense to me off of a press release, because OpenAI announced the same thing in October 2025 — they didn’t ship the software, and nothing happened to their stock. Just another announcement. In other words, Anthropic’s momentum has bought it credit for everything. And yes, it is madness, I love it, I use it, I pay for it, heavily. But does it deserve credit for everything it says? No. Nobody has that credit — not my mother, not God. Everything has to be analyzed.
I thought that was enough, and when I came back from vacation I ran into Mythos: more press releases about the same thing. A model so dangerous it sounds like plutonium. The idea was almost to sell it as a weapon of mass destruction that only the good and the powerful could access. I review, and review, and review; with long and severe claims, they show it is almost the master key to any system, that hacking has changed, and that the world is over. I start looking — with AI, obviously — for the confusion matrices and F-scores of the process. That is: in the search for those 500 or 1,000 vulnerabilities, how many did the model report as vulnerabilities that weren’t? In other words, for every confirmed real vulnerability, how many false positives were reported? Information not available. I look for how much compute, how many tokens — at prices for mortals like us — were used in the full process. Information not available. I look for CVEs growing at a scale matching the noise: not there. I look for an uptick in public exploit databases: no exponential increase. I look for information on the architecture of the process and, although we have some details, there is no real clarity there either. That last part I understand better.
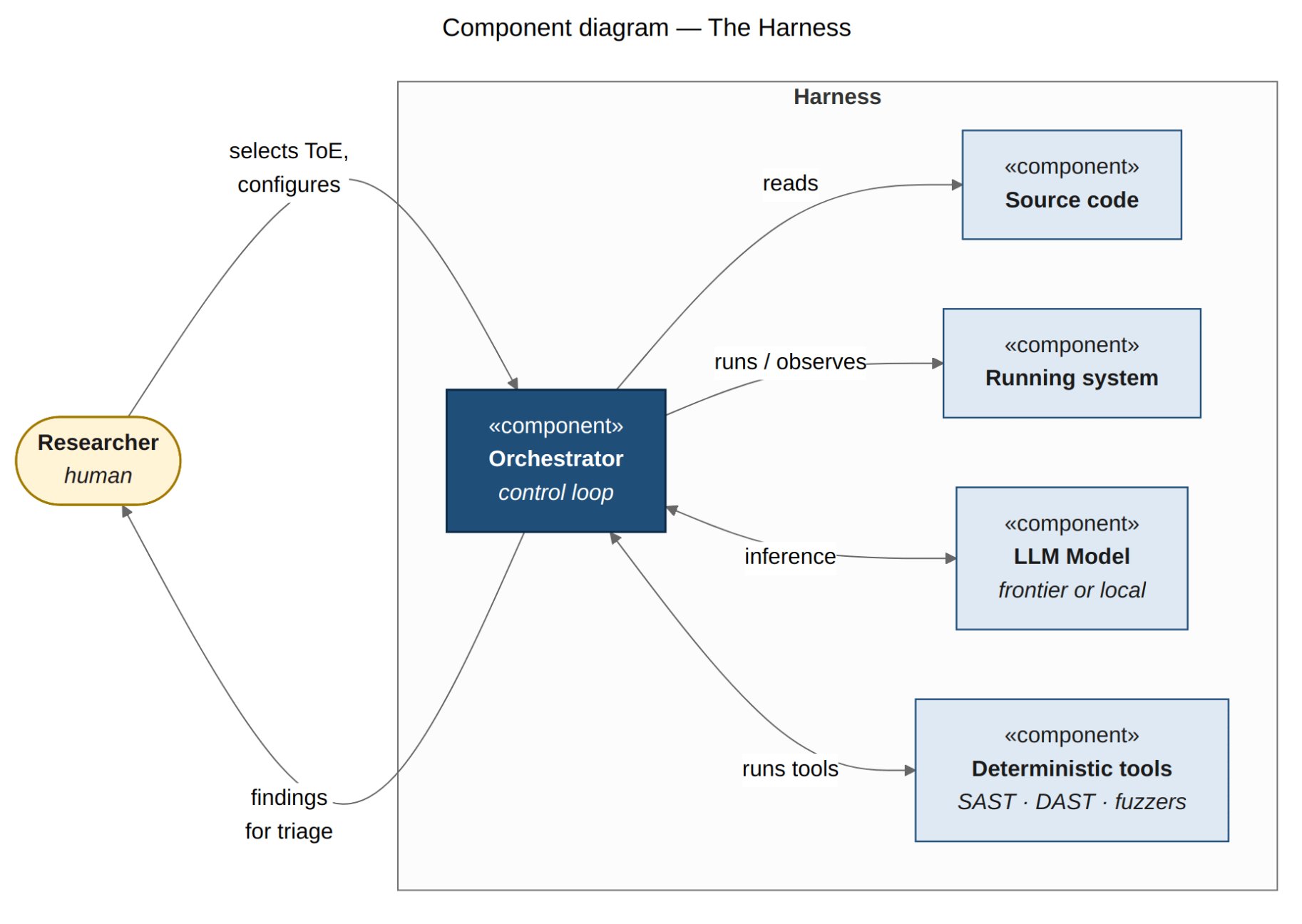
Now, let’s understand this: vulnerabilities and the process of finding them require the following — the source code of the system, the running system, deterministic tools coordinated by the model (that’s why it’s an agent), and all of this inside an infinite feedback loop in which files get prioritized, vulnerabilities get searched for, and through execution, real findings are triaged from the noise. You can imagine that this whole setup, for something like OpenSSL — as mature as it may seem — is easier to assemble than standing up an ERP, a CRM, or a distributed system. Building that setup is called a harness, and a human builds it. A human selects the ToE, a human assembles the harness and, more importantly, someone — after infinite outputs of candidate vulnerabilities — confirms whether they’re real or not. The process of discovering vulnerabilities with seriousness and responsibility is a process with tools, yes, but one where humans play a relevant and beautiful role. And it is so for the good of all. So much so that now, in the world of automation, a human at Anthropic says: don’t ship the software to production, only sell it to your friends first.
The worst moment hadn’t arrived yet. Over the following days, friends, enemies, clients, peers, strangers, family members barely aware of the topic, repost and forward shallow journalism that is the leftover of another announcement. The announcement of the announcement, everyone surfing the hype. Everyone caught up in the master-key frenzy, chasing more clicks for their posts; few, very few, retweet the people trying to break down the scope and the moving parts of this. That’s why I decided to write this article: because I can’t transmit this much information — against this much disinformation — with a simple voice note. I went back to blogging, in this case to get back at those who forward in a second: I’ll respond properly, stealing 30 minutes of their time with the longest article of my life.
An analogy and a question have helped me explain both the problem and the solution, without ignoring that the trajectory here is impressive and that in the future we will have a better world. Question: in the long run, will we have more vulnerabilities or fewer than today? Ask yourself before going on. The answer is simple through this analysis: we will have more programmers than today — this got democratized. Those programmers will produce more lines of code per person than before — LLMs are beautiful. And we will have fewer vulnerabilities per thousand lines of code, no doubt. Will the security they vomit out be better? The data today doesn’t show that; today they spit out more vulnerabilities than a human does. But, for the sake of argument, let’s assume the process improves along the trajectory it’s on. More programmers, more lines of code, and lower density give you more vulnerabilities deployed in the world. Not fewer. Because the quantity of lines of code being created today is so disproportionately higher — orders of magnitude above the improvement in vulnerability density — that it generates a larger attack surface, with more nominal vulnerabilities. Ergo: more incidents. Just like efficient LED bulbs didn’t lower consumption, they raised it: we bought more bulbs and lit up more spaces.
The analogy, for its part, is this. If an LLM always responds with good spelling, why doesn’t the LLM always respond with good code? Why, in spelling, aren’t we sold two products — the one that writes and the one that corrects the spelling — but in security we are sold two products: the one that writes code and the one that corrects code? What does spelling have that security and vulnerabilities don’t? In the answer to this there are beautiful things, said by the very same frontier-model providers. Spelling, unlike security, is local, deterministic, non-adversarial, and of low asymmetric cost. Security, in contrast, is global, contextual, adversarial, and of high asymmetric cost.
Spelling is local because a few elements in a paragraph are enough to judge whether a word is right or wrong. That’s what lets it be embedded inside the model. A vulnerability is global because it arises from the chaining of many moving parts: an unfiltered input in a file, the destination of that information in a database, an incorrect dependency, a misconfiguration, or any combination thereof. Many pieces make up a vulnerability. Spelling is deterministic because there is a revealed truth: there are language academies that say “these are the rules,” period, no debate. In vulnerabilities, determinism is a dream: what’s a vulnerability in one system or one use case isn’t in another. In spelling, nobody is trying to hurt someone else because an accent is missing here or there; in security there is the adversarial side, where people are constantly hunting for flaws to cause damage. And finally, spelling has a low asymmetric cost — you look bad if you write badly — but in security, if you have a vulnerability, the cost to your company’s image and to your users is much greater than looking bad: it involves money, serious money, and even lives.
There is something even deeper behind this difference, and it's worth naming. Since Turing in 1936, we have known that no algorithm can decide, for an arbitrary program, whether it will terminate. Rice's theorem, a direct corollary, extends the result: any non-trivial semantic property of a program — "does it have a security bug?", "does it never dereference a null pointer?", "is it equivalent to this other one?" — is equally undecidable. It isn't that we don't yet know how to solve it: it can be proven that no algorithm can, in the general case. That's why every SAST, every type checker, every model checker is, by construction, an approximation: it either over-reports with false positives, or under-reports with false negatives. There is no escape, and there never will be. That's why TLA+, Coq, and Lean4 require a human to supply annotations, invariants, and tactics to close the gap. Spelling is decidable. Security is not, and never will be. The difference between the two products isn't a lack of engineering: it's computability theory.
Again, I insist: why are there two products and not one? Why doesn’t it vomit out perfect code in one shot?
This avalanche of information has produced something very positive: an urge to remediate, a concern about security. And I ask myself: why now? Because of an announcement? Well, the “why” of how they reach a good conclusion through a flawed process shouldn’t really matter to me. But it worries me, because when you conclude that way, today it’s good and tomorrow it’s bad. That is, there’s no consistency, no method, no system: we react to fear. I forget that people are inherently irrational and that the actual course of decisions really is like this. But it makes me sad. And more paradoxical still: many organizations already have vulnerabilities we reported to them long ago, through similar processes, and today they’re writing about how costs will drop, whether AppSec will disappear, whether hackers will become unnecessary, and what they should do to protect themselves from this new threat. The only thing they need to do is worry about remediating their backlog of vulnerabilities — which people have been postponing out of sheer laziness, wasting time prioritizing — when in reality it is possible to remediate all of it if the internal processes are put in place, at highly reasonable values.
With all that in mind, here is my response to everyone forwarding links: the models are advancing impressively, and we embrace it with excitement; but today the density of vulnerabilities has grown, not dropped. I do believe it will drop in the future, but even so we will have more vulnerabilities, not fewer. Incidents will be larger. The models, trained on insecure code, are propagating many vulnerabilities today. The frontier-model providers killed the spell-checker industry because spelling is local, deterministic, non-adversarial, and of low asymmetric cost; but vulnerabilities are global, contextual, adversarial, and of high asymmetric cost. And finally, a model doesn’t find vulnerabilities: a system, a pipeline, finds vulnerabilities. A system made of a harness around a running system, its source code, deterministic tools that the model orchestrates in order to find vulnerabilities, and a human who assembles all of that for each particular system and who then triages an output that is never perfect. And a system like this, is model agnostic, doesn’t even require frontier models: older, cheaper models are already being used to find vulnerabilities economically today, so the marginal gain from the frontier is smaller than the headlines suggest.
What worries me most is the misallocation of attention. Most organizations already have a backlog full of known vulnerabilities they are not remediating. They know exactly what is broken, and they are not fixing it. Yet they are anxious about a hypothetical master key that opens everything and hasn’t even shipped to production, when what they should be doing, with discipline, is remediating what they already know is wrong.
P.S: Vomited straight from my brain, no spellcheck, no human revision afterwards, then run through the prompt: "fix spelling, grammar, and narrative coherence". And that result run through another: "translate to English". All of it by Opus 4.7 Adaptive.